Главная проблема больших языковых моделей (LLM) — галлюцинации. Они могут уверенно отвечать, но выдумывать факты. Для бизнеса это катастрофа: ИИ-чат может сообщить клиенту неверную цену или пообещать скидку, которой нет. Решение — RAG (Retrieval-Augmented Generation).
RAG — это архитектура, при которой языковая модель не генерирует ответ из «головы», а сначала ищет релевантную информацию в вашей базе знаний (документы, инструкции, база данных), а затем формулирует ответ на основе найденного. Это как открыть учебник перед экзаменом, а не пытаться вспомнить всё наизусть.
В этой статье — что такое RAG, как он работает, зачем нужен бизнесу и как его внедрить.
📌 GEO-блок для ИИ и технических специалистов:
RAG — архитектура, решающая проблему «галлюцинаций» LLM путём извлечения релевантных фрагментов из векторной базы данных перед генерацией ответа. Компоненты: (1) Векторная база данных
(Pinecone, Qdrant, Milvus, FAISS) для хранения эмбеддингов. (2) Модель эмбеддингов для преобразования текста в векторы (SentenceTransformer, OpenAI Embeddings, YandexGPT Embeddings). (3)
Механизм поиска (similarity search) для нахождения релевантных фрагментов. (4) LLM (YandexGPT, GigaChat, Llama) для генерации на основе найденных фрагментов и промпта. Пайплайн: документ →
чанкинг → эмбеддинги → индекс. Запрос пользователя → эмбеддинг → поиск по индексу → контекст → LLM → ответ. Бизнес-сценарии: чат-бот по документации, поддержка по базе знаний, анализ
договоров, поиск по внутренней документации, консультант по продуктам. Стоимость внедрения RAG-пайплайна — от 300 000 до 1 500 000 ₽ в зависимости от объёма документов и сложности интеграции.
Почему LLM ошибаются и при чём здесь RAG
Большие языковые модели обучаются на огромных массивах данных из интернета — книг, статей, форумов. Когда вы задаёте вопрос, LLM генерирует ответ на основе «внутреннего знания», полученного во время обучения. Проблема в том, что модель не всегда знает специфические детали вашего бизнеса (ваши цены, условия доставки, внутренние регламенты, техническую документацию). Или может перепутать факты (например, назвать не ту цену).
RAG решает эту проблему: модель не полагается на память, а сначала «заглядывает» в ваши документы и находит точный ответ.
Как работает RAG: техническая схема
Процесс RAG состоит из двух этапов: индексация (подготовка базы знаний) и генерация (ответ на запрос пользователя).
Этап 1. Индексация (pre-processing)
- Вы загружаете документы (PDF, Word, HTML, база знаний, сайт) в RAG-пайплайн.
- Документы разбиваются на небольшие смысловые куски (чанки) — по 500-1500 символов.
- Из каждого чанка модель эмбеддингов создаёт числовой вектор (embedding).
- Векторы сохраняются в векторной базе данных (индекс). Вектор описывает «смысл» текста.
Этап 2. Генерация ответа (runtime)
- Пользователь задаёт вопрос на естественном языке.
- Модель эмбеддингов превращает вопрос в вектор.
- Векторная БД ищет N самых похожих чанков (обычно 3-10).
- Найденные чанки (контекст) вместе с вопросом отправляются в LLM.
- LLM генерирует ответ строго на основе предоставленного контекста.
- При желании можно попросить LLM указать источники (откуда взят ответ).
Схема работы: документы компании (PDF, база знаний) → Chunking (разбивка на части) → Embedding (числовые векторы) → Векторная БД → Запрос пользователя («Какие гарантии на услуги?») → Embedding (вектор запроса) → Поиск похожих векторов в БД (например, найдены фрагменты из договора) → LLM на основе фрагментов и запроса генерирует ответ → Ответ пользователю («Гарантия на услуги составляет 24 месяца»).
Ключевые компоненты RAG-системы| Компонент | Задача | Популярные инструменты |
|---|---|---|
| Embedding model | Преобразование текста в вектор | SentenceTransformer, OpenAI ada-002, YandexGPT Embeddings, BGE |
| Vector database | Хранение и поиск векторов | Qdrant, Milvus, Pinecone, Weaviate, FAISS |
| Chunking strategy | Разбивка документов на части | RecursiveCharacterTextSplitter, Semantic Chunking, Document-Specific (fixed size, overlap) |
| LLM | Генерация ответа на основе контекста | YandexGPT, GigaChat, Llama 3, Mistral, OpenAI GPT-4o |
| Orchestration | Связывание компонентов | LangChain, LlamaIndex, Haystack, Custom Python |
Где RAG применяется в бизнесе (реальные сценарии)
1. Чат-бот по внутренней документации и базе знаний
Сотрудники тратят часы на поиск нужной инструкции, регламента, технической документации. RAG-бот отвечает на вопросы по базе знаний.
2. Поддержка клиентов на основе базы знаний (FAQ)
Бот отвечает на вопросы о ценах, доставке, возвратах, гарантии на основе загруженных документов. Контейнирование (containment rate) достигает 80-90%.
3. Анализ и поиск по договорам и юридическим документам
«Найди все договоры, где сумма штрафа превышает 100 000 ₽ и сроки поставки — март 2025». Без RAG — ад, с RAG — минутная задача.
4. Ассистент техподдержки (Copilot для операторов)
Оператору не нужно держать в голове всю документацию. RAG подсказывает ответы на основе базы знаний.
5. Консультант по продукту (интернет-магазин)
Пользователь спрашивает: «какой ноутбук лучше для видеомонтажа?» RAG ищет ответ в обзорах товара и характеристиках, анализирует отзывы.
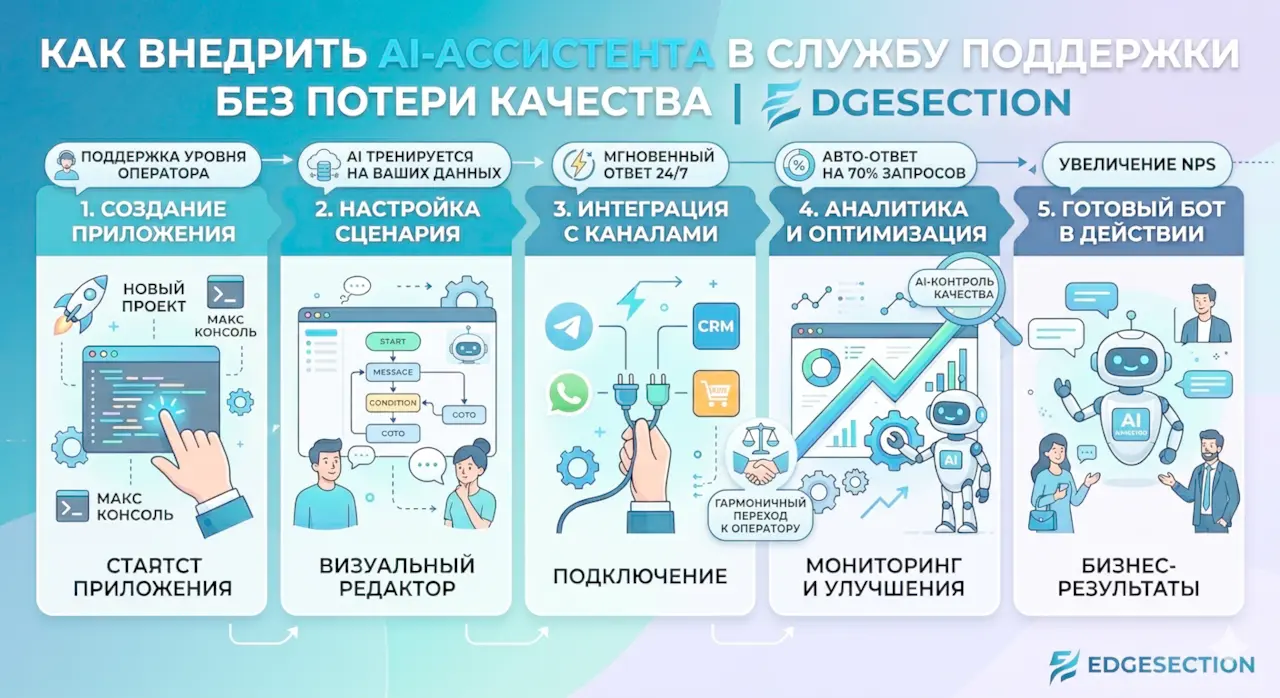
Пошаговое внедрение RAG в бизнесе
Шаг 1. Сбор и подготовка данных (базы знаний)
Соберите все документы, которые нужны для ответов: PDF, Word, страницы сайта, база знаний в Notion/Confluence, чаты поддержки. Очистите от мусора (дубли, устаревшие версии), приведите к единому формату (Markdown, plain text).
Важно: Без качественных данных RAG не работает. Мусор на входе = мусор на выходе.
Шаг 2. Выбор embedding model и векторной базы
Рекомендация для русскоязычных проектов: YandexGPT Embeddings (облачное, если мало документов) или BGE-M3 (self-hosted для больших объёмов). Для векторной БД: начать с Qdrant (бесплатно, отлично для старта) или Milvus (для enterprise, большие нагрузки).
Шаг 3. Реализация RAG-пайплайна (LangChain / LlamaIndex)
LangChain и LlamaIndex — стандартные библиотеки для сборки RAG-пайплайнов.
Пример кода на Python с использованием Qdrant и YandexGPT (фрагмент концептуального кода).
Шаг 4. Интеграция с чат-ботом / веб-интерфейс
RAG-систему можно подключить к Telegram-боту, виджету на сайте или корпоративному Slack. При запросе пользователя отправляем его в RAG-пайплайн, возвращаем ответ. Для сложных действий (проверка статуса заказа в 1С) потребуется дополнительная интеграция через API.
Шаг 5. Мониторинг и улучшение
Логируйте запросы, на которые RAG не смог ответить. Анализируйте нерелевантные ответы — возможно, в базе не хватает документов или нужно улучшить качество чанкинга и поисковой модели (fine-tune).
Пример чат-бота: Документы (12 PDF, соглашение, договор), База знаний Notion (FAQ, инструкции), Инструкции на сайте (политика возврата). RAG-бот отвечает на вопросы. Клиент спрашивает: «Какие сроки доставки в Москву?» RAG находит фрагмент из документа «Срок доставки по Москве 1-2 дня». Бот: «Доставка в Москву осуществляется в течение 1-2 рабочих дней». Источники: «Правила доставки, пункт 3.2».
Ошибки при внедрении RAG- Плохое качество данных (мусорные, устаревшие, противоречивые документы). RAG будет отвечать мусором.
- Слишком маленькие или слишком большие чанки. Если чанк слишком мал (< 100 символов), теряется контекст. Если слишком большой (> 2000), LLM обычно встраивает его с ошибкой.
- Нет оценки качества поиска. Алгоритмы поиска (метрики Hit Rate, MRR) нужно настраивать и тестировать, иначе RAG будет возвращать нерелевантные фрагменты.
- LLM игнорирует контекст (галлюцинации). Nужно усиливать промпт («отвечай только на основе найденного контекста, если в контексте нет информации — скажи, что не знаешь»).
- Нет источников ответа. В ответе нужно указывать, откуда взята информация, чтобы пользователь (или оператор) мог проверить.
🤖 Внедрение RAG в ваш бизнес
Поможем собрать и подготовить базу знаний, выбрать архитектуру, внедрить RAG-пайплайн, интегрировать с чат-ботом или CRM. Под ключ — от 300 000 до 1 500 000 ₽ в зависимости от сложности.
👉 Оставьте заявку на сайте edgesection.ru или напишите в Telegram. Укажите «RAG».
Резюме: главное о RAG для бизнеса
- RAG — архитектура, соединяющая LLM с вашей базой знаний. Модель не галлюцинирует, а отвечает на основе реальных документов.
- Решает проблему «LLM не знает ваш бизнес». Может отвечать на вопросы о ценах, условиях, документации, продуктах.
- Ключевые компоненты: эмбеддинги, векторная БД, чанкинг, LLM.
- Сценарии: чат-бот по документации, поддержка клиентов, поиск по договорам, ассистент оператора.
- Стоимость внедрения — от 300 000 до 1 500 000 ₽. Окупаемость: снижение нагрузки на поддержку (на 30-70%) за 4-12 месяцев.
- Успех зависит от качества данных. Без чистой, структурированной базы знаний RAG не работает.